Understanding LSTM Networks and Their Contribution to Solving RNN Problems
Machine learning enthusiast with a strong emphasis on computer vision and deep learning. Skilled in using well-known machine learning frameworks like TensorFlow , scikit-learn and PyTorch for effective model development. Familiarity with transfer learning and fine-tuning pre-trained models to achieve better results with limited data. Proficient in Python, Machine Learning, SQL, and Flask.
Long Short-Term Memory (LSTM) networks are a type of artificial recurrent neural network (RNN) that have been designed to address significant challenges with traditional RNNs.In the previous article, we deep-dived into RNN's In this blog post, we will explore the intricacies of LSTM networks and their contributions to solving problems encountered within RNNs, such as the vanishing gradient issue.
Problems with Standard RNNs
Vanishing Gradient Problem: One of the main challenges faced by standard RNNs is the vanishing gradient problem. As the network trains through backpropagation, gradients can become exceedingly small as they move backwards through time. When this occurs, the gradients vanish, making it challenging for the network to learn from earlier time steps effectively. This results in poor performance when handling long-term dependencies.
Exploding Gradient Problem: This issue is the opposite counterpart to the vanishing gradient problem. Gradients may also grow unbounded during training, causing large updates and making the model unstable.
The Advent of LSTM Networks
To address these shortcomings, LSTMs offer enhanced learning capabilities by managing both short-term and long-term dependencies in sequential data.
LSTMs consist of memory cells responsible for storing information over extended periods. Along with these memory cells, LSTMs incorporate three distinct gates: input gate, output gate, and forget gate.
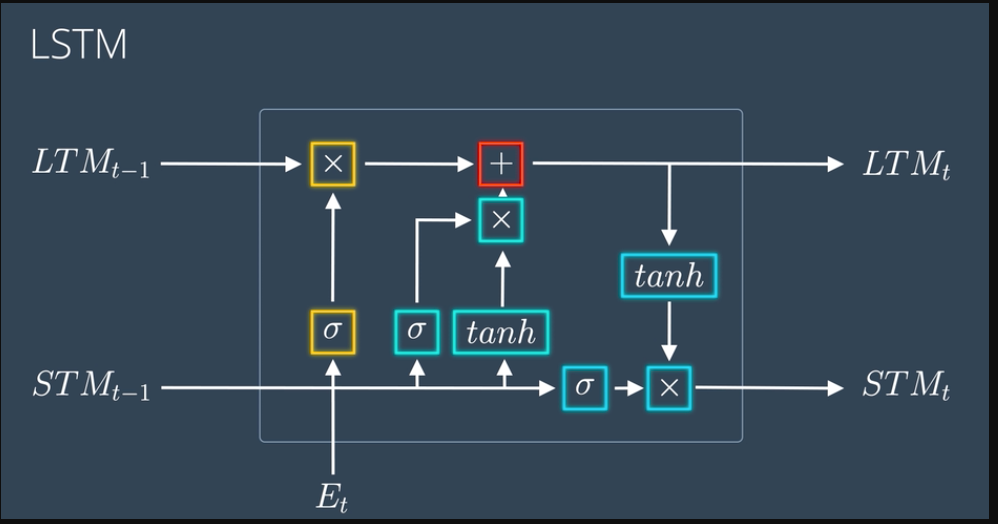
So, how do LSTMs Solve RNN Problems?
Input and Output:
An LSTM network takes a sequence of input data as input, where each element in the sequence has multiple features or dimensions.
It produces a sequence of outputs of the same length, where each output element corresponds to a particular input element.
Memory Cell:
At the core of an LSTM is the memory cell, which is responsible for storing and updating long-term information.
The memory cell maintains its state over time, allowing the network to remember information from earlier time steps.
Gates:
LSTMs use gates to control the flow of information into and out of the memory cell.
There are three types of gates in an LSTM: input gate, forget gate, and output gate. Each gate is implemented using a sigmoid activation function.
Input Gate:
The input gate determines how much of the new input should be stored in the memory cell.
It takes the current input and the previous output as inputs and outputs a value between 0 and 1 for each dimension of the input.
Forget Gate:
The forget gate decides what information to discard from the memory cell.
It takes the current input and the previous output as inputs and outputs a value between 0 and 1 for each dimension of the memory cell state.
A value of 0 means "completely forget," while a value of 1 means "completely remember."
Update Memory:
The input gate and forget gate values are used to update the memory cell state.
The input gate output is multiplied by the candidate values (proposed changes) for the memory cell state, which are generated by a tanh activation function.
The forget gate output is multiplied by the previous memory cell state to determine which values to retain.
Output Gate:
The output gate determines how much of the current memory cell state should be output.
It takes the current input and the previous output as inputs and outputs a value between 0 and 1 for each dimension of the memory cell state.
The output gate output is multiplied by the updated memory cell state, passed through a tanh activation function, and produces the final output of the LSTM cell.
Multiple LSTM Cells:
In practice, an LSTM network consists of multiple LSTM cells stacked together.
Each LSTM cell takes the output of the previous cell as input and produces its output, which becomes the input for the next cell.
Training:
During training, the parameters of the LSTM network, including the weights and biases of the gates, are learned using the backpropagation through time (BPTT) algorithm.
The network is trained to minimize a specific loss function, often using gradient descent optimization techniques.
Inference:
After training, the LSTM network can be used for inference, where it takes new input sequences and produces the corresponding output sequences.
The learned parameters are used to make predictions based on the learned patterns in the training data.
That's a high-level overview of how an LSTM network works.
Conclusion
LSTM networks have proved instrumental in improving performance when dealing with long-term dependencies in sequential data. By incorporating memory cells and gating mechanisms, LSTMs effectively address the vanishing gradient problem that arises in traditional RNNs. The memory cell allows the network to retain information over time, enabling it to capture long-term dependencies.
Hope you got value out of this blog. Subscribe to the newsletter to get more such informative blogs
Thanks :)